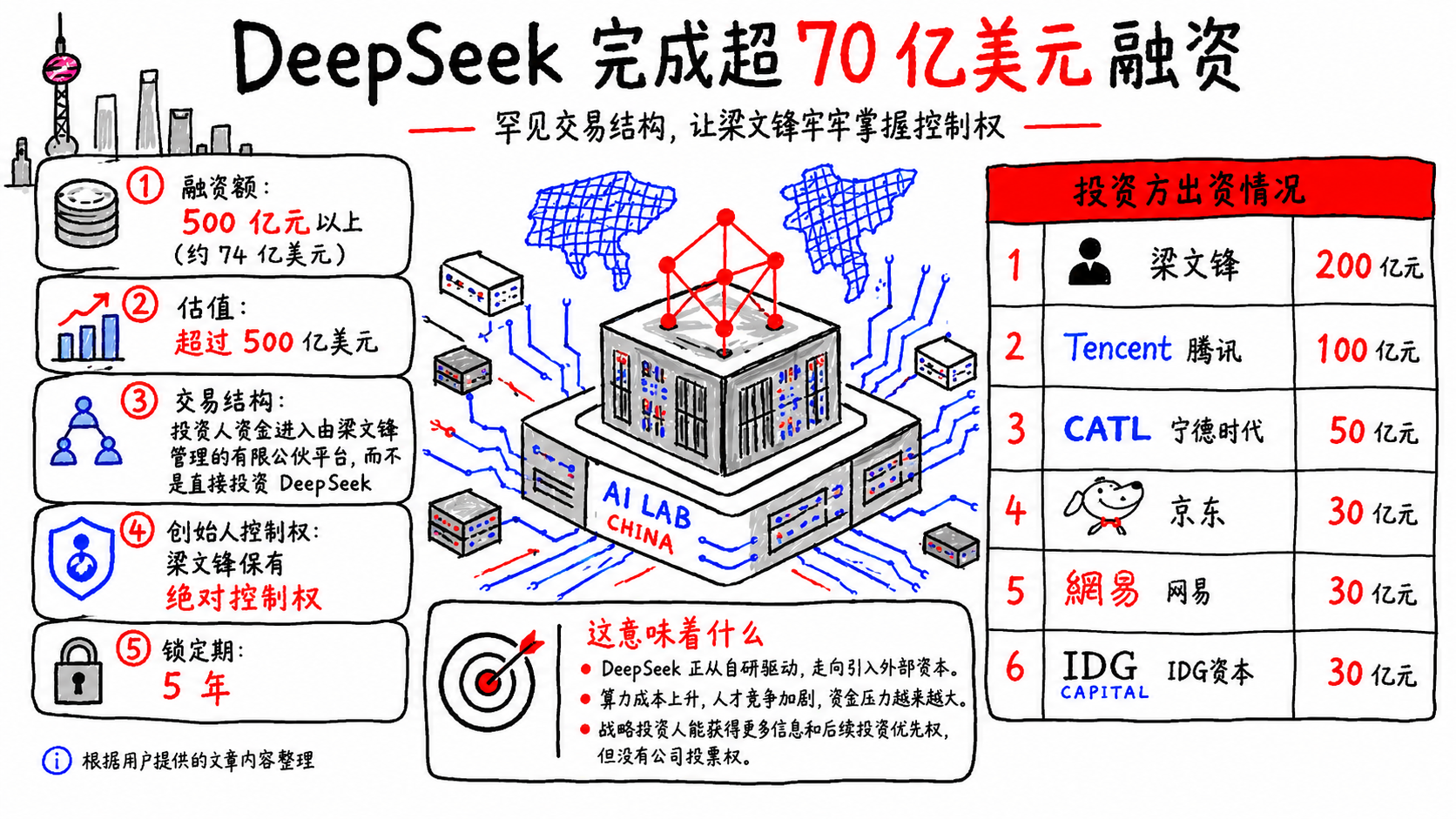
6月16日,DeepSeek首轮融资实锤的消息,直接炸穿了整个科技创投圈。就在一年多前,创始人梁文锋还公开立下“不融资、不上市、不商业化”的三不铁律,声称要拒绝资本干扰、死磕通用大模型技术,是整个AI圈出了名的“反资本异类”。最终披露的出资名单更耐人寻味,梁文锋个人掏200亿成最大单一出资方,腾讯、宁德时代、网易、京东等产业巨头包下了绝大多数份额,红杉、高瓴这类常年抢食明星项目的顶级财务VC,反倒只站在了边缘席位。量化私募的赚钱逻辑,说穿了就是“代客理财+收益分成”。帮客户管钱,每年固定收1%左右的管理费(不管盈亏都收),投资赚了钱,再从利润里提20%的业绩报酬,这是行业通用的“二八分账”规则。按公开可查的数据,幻方量化管理规模稳定在700亿元以上,2025年全年平均收益率达到56.55%,在百亿级量化私募里排行业第二。梁文锋作为幻方的控股股东,直接和间接持股超54.89%,每年光分红就能拿到大几十亿。从2015年创立幻方到现在,十年下来,个人积累几百亿身家是完全合理的。但这次掏出200亿,还真不是随便一掏,相当于把自己大半的流动身家都押在了DeepSeek上,绝非随便拿点零花钱试水。而幻方本身就是国内最早大规模用GPU做AI训练的机构之一。2019年就砸钱建了“萤火一号”算力集群,装了1100块英伟达显卡;2021年又砸10亿搞“萤火二号”,直接上了1万张显卡,算力规模在当时的量化圈里独一档。换句话说,梁文锋早在做AI大模型之前,就已经是算力圈的老玩家了,对算力成本、集群建设、产能调度的理解,比绝大多数AI创业者都深得多。梁文锋的幻方量化背景,是整个交易最底层的逻辑来源,量化圈的容量管理+收益分层思路,降维用到了AI算力生意里。做量化对冲基金的核心能力,从来不是收益率最高,而是“容量管理”,先精准测算策略能容纳的资金规模,再匹配对应的仓位与交易节奏,用自有资金做安全垫平滑波动,全程把风险控制在自己手里,绝不盲目扩张规模。这套思路被完整平移到了DeepSeek的算力生意里。用创始人个人出资做风险垫,保证产能交付的信用,对冲建设周期里的不确定性;用五年锁定期过滤短期资本,避免算力建设被短期套现诉求打乱节奏。而更深层的移植,是量化产品的“收益分层设计”思路。量化私募里常把产品拆成不同份额,优先级拿固定收益、劣后级拿超额收益,不同份额对应不同的权责和回报。这轮融资本质也是同一套逻辑,红杉、高瓴这类常年霸占明星项目核心席位的顶级财务VC,全程站在边缘;而腾讯、宁德时代、京东、网易等产业资本,直接包下了绝大多数出资份额。创始人份额拿控制权+全部剩余收益,产业资本份额拿算力服务权+基础收益权,财务VC份额拿纯财务收益权。不同出资方各取所需,互不干涉,权责边界从一开始就划得清清楚楚,区别于多数AI公司的融资路径,量化式的精细风控。出资方也都精明的很,腾讯掏的100亿、宁德时代掏的50亿,如果拿去公开市场租昇腾910B算力集群,按当前市价折算,这笔钱撑死能用2-3年,还得排队等产能、抢优质机位,随时面临涨价和断供风险。而换成投资DeepSeek,不仅能锁定未来数年的专属算力配额与调用优先级,还能白拿一笔公司股权。这场刷新纪录的融资,从根上就不是创投圈那套股权增值游戏,而是一场针对国产高端算力的“预售式众筹”,股东身份是附赠的收益凭证,稳定的算力产能才是产业方真正要抢的硬通货。而梁文锋个人掏出的200亿,也远不止“巩固控制权”这一层,它更像一笔“产能交付保证金”,以创始人的全部个人身家为信用锚,向所有产业出资方承诺算力集群的建设进度、交付质量与调用优先级。配合交易架构里“五年锁定期、外部投资方无投票权”的设计,双方的权责边界极其清晰,投资方不要干涉日常运营,不要惦记短期套现,你出钱,我给你稳定的全链路算力服务+长期股权收益;我拿钱,专心搞产能建设、做技术迭代,不用被短期财务回报绑架节奏。如果这套模式跑通,重构的就不仅仅是收入结构,而是整个AI算力生意的成本摊销逻辑。它跳出了行业通用的“高端定制+普惠API”的收入分层框架,本质是用“产能确权+边际变现”的两层架构,把重资产的算力生意做成了可量化管控的容量生意。普通定制是客户按项目签服务合同,按交付里程碑付款,厂商靠服务差赚溢价;而配额确权层是客户提前出资,锁定算力集群的长期产能优先分配权,这笔钱直接冲抵算力基建的固定成本,本质是把未来的产能使用权打包成了资产份额。对DeepSeek来说,这部分资金到账的那一刻,万卡级集群的芯片采购、机房建设、折旧摊销等全部固定开支就已经被覆盖,不用再靠后续营收慢慢回本,从根源上消解了重资产行业的产能闲置风险。对出资方来说,拿到的也不是单次的项目服务,而是长期的产能话语权,只要集群在,就有稳定的算力额度,不用跟着市场行情抢产能、扛涨价。第二层是边际产能变现层,也就是公开市场的API调用业务。同行做API零售,定价里要包含算力折旧、研发摊销、运营成本,有明确的毛利底线,价格战打到底也不能亏着卖。但DeepSeek的这部分产能,是固定成本被完全覆盖后剩下来的闲置算力,定价只需要覆盖电力、带宽等边际成本,没有任何折旧压力。这才是它能把推理价格打到行业地板价的真正底气,别人卖Token是做生意,要算盈亏,它卖闲置产能是清库存,卖多少赚多少。配额层的产业方贡献真实的工业、互联网、电商场景数据,帮模型持续迭代能力;模型能力越强,边际层的API产品竞争力就越强,能吸引更多零散客户;边际层的营收又可以反哺新的算力基建,进一步扩大配额层的权益总量。这套架构跑通后,行业竞争会从“技术比拼”升级成“成本结构的降维打击”。中小玩家既拿不到芯片产能,也拿不到前置的产业资金,算力基建的固定成本要靠自己一点点扛,API定价永远有成本底线。当头部玩家靠配额层抹平了固定成本,用边际成本打价格战时,中小玩家连跟进的资格都没有,你卖一单亏一单,人家卖一单赚一单,根本不在同一个赛场上。当然,这套模式并非没有风险,它的成立前提是DeepSeek能持续稳定地交付算力与技术迭代能力。目前所有的算力配额、定制服务承诺,都是绑定在股权上的隐性约定,没有标准化的服务合同明确交付标准、违约条款、退出机制。未来如果公司股权结构变动、业务方向调整,配额权益能不能兑现、怎么兑现,都没有明确的法律保障。比起白纸黑字的算力租赁合同,这种“股权绑定的服务权益”履约弹性更大,风险也更高。另一方面,不同出资方的业务场景差异极大,工业场景要精度、互联网场景要速度、电商场景要垂直能力。多方向的定制需求会分散研发资源,倒逼模型走向碎片化,反而拖累通用模型的迭代效率,最后可能出现“每个场景都适配了,但通用能力没跟上”的尴尬局面。当核心的算力服务现金流被前置拆分、通过股权形式变现后,公司未来的账面营收和利润会被大幅稀释,传统的PE、PS估值模型会失去锚点。后续再融资乃至上市时,二级市场投资者很难用常规方法给公司定价,反而可能出现估值倒挂的问题。在国产高端算力供需错配的当下,这依然是一笔跳出了传统创投框架的、极其务实的商业设计,这套用需求抱团,补供给短板的思路,或许才是这笔500亿融资真正的价值。